
Introduction to Puppeteer and web scraping
In this article, we will set up a NodeJs project that will scrape https://react.dev/ and print some content from their homepage in the console.
Free API
Before we start, I would like to highlight that we have a free Web scraper API that we can use to do this work for us, so if you are interested go ahead and take a look at it.
Set up our project
Let's go ahead and create our project
mkdir scraper cd scraper npm init -y npm i puppeteer touch index.js
Set up our scraper
In our index.js, we start by setting up our Puppeteer and launch a browser.
const puppeteer = require("puppeteer"); const scrapeReact = async () => { try { const browser = await puppeteer.launch({ headless: "new" }); } catch (err) { console.log(`Error while checking site. Full error: ${err}`); } };
In above code, puppeteer will launch a new browser that we can use to enter a website and read its content.
Navigate to the page
Next, we will open a new page and navigate to https://react.dev/.
const page = await browser.newPage(); await page.goto("https://react.dev/", { waitUntil: "domcontentloaded" });
Now our crawler will enter the react.dev web page and wait until the content has loaded. Note that domcontentloaded will also work on client side rendered pages :)
Read content from the web page
Now, we will read some content from the page. We will grab the first <h1> and also the first text with the class called .text-4xl and take the text from them and return in an object.
How to know what to read?
Doing these kind of things, requires some "digging" in how the HTML looks so we know what to look for. So you need to visit the page you want to scrape, and check how the HTML structure looks like. Below I will share an image of how our elements looks in a normal browser.
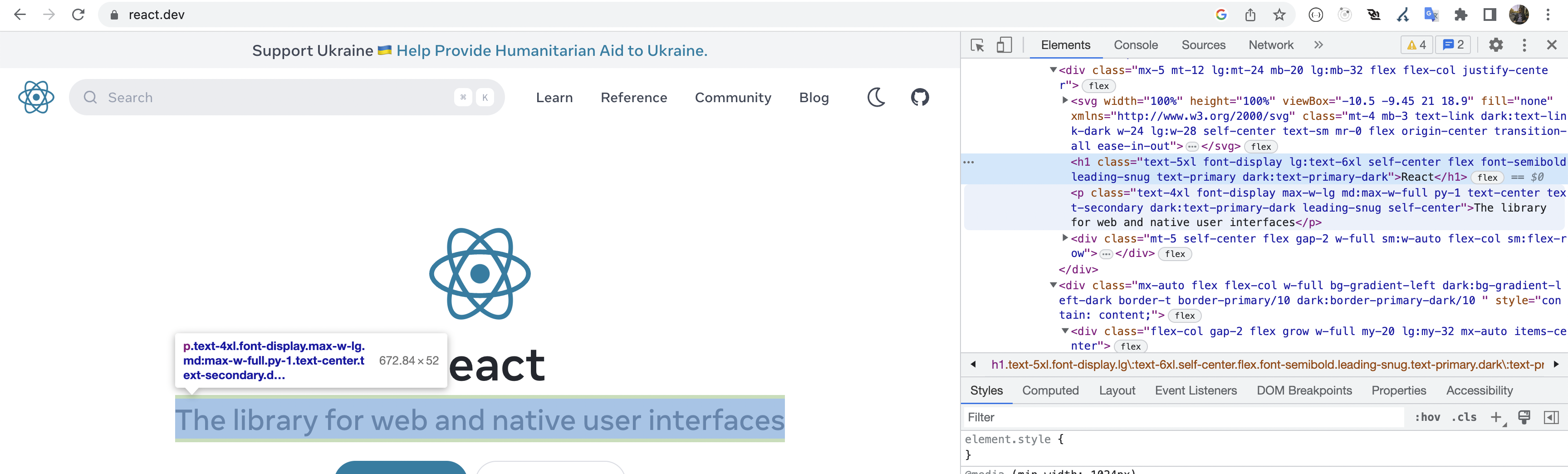
So by inspecting the elements, we can figure out what we want to search for when grabbing content etc.
In code
Below is how we can retrieve it in code using querySelector, just like the normal way of getting elements and HTML content in JavaScript.
const content = await page.evaluate(() => { return { headline: document.querySelector("h1").innerText, text: document.querySelector(".text-4xl").innerText, }; });
Full code
Below is our full code of our scraper
const puppeteer = require("puppeteer"); const scrapeReact = async () => { try { const browser = await puppeteer.launch({ headless: "new" }); const page = await browser.newPage(); await page.goto("https://react.dev/", { waitUntil: "domcontentloaded" }); const content = await page.evaluate(() => { return { headline: document.querySelector("h1").innerText, text: document.querySelector(".text-4xl").innerText, }; }); console.log(content); await browser.close(); } catch (err) { console.log(`Error while checking site. Full error: ${err}`); } };
Start scraping
Now, we will invoke our function and see what we will get in the console.
Add this in the bottom of the file
(async () => { await scrapeReact(); })();
And then in the terminal:
node index.js
And in the console, we should see something like this.
{ "headline": "React", "text": "The library for web and native user interfaces" }
Outro
In this guide, we learned how to scrape a very basic web page using Puppeteer and created an object with the content we retrieved. As said, this was a very simple example, but it is more than enough to get started to crawl websites and get web content. Puppeteer offers so much more, and can also be used to do automation testing etc to test out your web application and make sure everything is working as intended. You can read more here.
If you have a project and want to deploy it to a server, we have a guide on how to do it with Docker, read it here.
Thanks for reading, and have a great day!
 Tue May 30 2023
Tue May 30 2023 How to create and decode QR codes in NodeJsIn this tutorial, we will show how we can create QR codes using NodeJs and also how to decode already created QR codes.
How to create and decode QR codes in NodeJsIn this tutorial, we will show how we can create QR codes using NodeJs and also how to decode already created QR codes. Build a full stack application with React and NodeJsA tutorial on how to build a simple full stack application with React in the client side and NodeJs in the backend.
Build a full stack application with React and NodeJsA tutorial on how to build a simple full stack application with React in the client side and NodeJs in the backend. How to convert a text file and its content to a JSON file with correct structureA guide on how to create a JSON file from a txt file in NodeJs. We will also make sure that the content is formatted in correct JSON format.
How to convert a text file and its content to a JSON file with correct structureA guide on how to create a JSON file from a txt file in NodeJs. We will also make sure that the content is formatted in correct JSON format. How to send email in NodeJs with Gmail - using nodemailerA guide on how to use Gmail and Google OAuth 2.0 to send emails with NodeJs and nodemailer.
How to send email in NodeJs with Gmail - using nodemailerA guide on how to use Gmail and Google OAuth 2.0 to send emails with NodeJs and nodemailer. How to send email in NodeJs with a Yahoo mail using nodemailerA tutorial on how to send emails in NodeJs using nodemailer. Our sender email will be a Yahoo address and we will cover how to authenticate using app passwords.
How to send email in NodeJs with a Yahoo mail using nodemailerA tutorial on how to send emails in NodeJs using nodemailer. Our sender email will be a Yahoo address and we will cover how to authenticate using app passwords. Fast and easy way to secure your Node express API using HelmetA quick guide on how to secure a Node express API with helmet.
Fast and easy way to secure your Node express API using HelmetA quick guide on how to secure a Node express API with helmet. Hash passwords in NodeJs using bcryptA tutorial on how to use bcrypt in NodeJs to hash passwords and compare them afterwards.
Hash passwords in NodeJs using bcryptA tutorial on how to use bcrypt in NodeJs to hash passwords and compare them afterwards. Setup puppeteer with DockerIn this guide we will show how to setup a puppeteer service in NodeJs with Docker.
Setup puppeteer with DockerIn this guide we will show how to setup a puppeteer service in NodeJs with Docker. Introduction to caching in a NodeJs APIIn this guide we will show how we can set up a simple cache in NodeJs. We will use node-cache library from npmjs.com in this article.
Introduction to caching in a NodeJs APIIn this guide we will show how we can set up a simple cache in NodeJs. We will use node-cache library from npmjs.com in this article. How to parse XML data to JSON in NodeJsIn this tutorial, we will show how we can parse XML in NodeJs in to a JSON object. We will use fast-xml-parser library in this guide.
How to parse XML data to JSON in NodeJsIn this tutorial, we will show how we can parse XML in NodeJs in to a JSON object. We will use fast-xml-parser library in this guide.